I am testing markdown, I have used cocalc.com to create a file and then saved the file as .md this helped me to create the file in gitbut to show in post
Example of a classifier
# EDA and data handling
import numpy as np
import pandas as pd
import pickle
# Modeling
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
# read in the data
# housing_train = pd.read_csv('/content/sample_data/california_housing_train.csv')
housing_train = pd.read_csv('california_housing_train.csv')
housing_train.shape
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-2-a4eec8bdb495> in <module>
1 # read in the data
2 # housing_train = pd.read_csv('/content/sample_data/california_housing_train.csv')
----> 3 housing_train = pd.read_csv('california_housing_train.csv')
4 housing_train.shape
/usr/local/lib/python3.6/dist-packages/pandas/io/parsers.py in parser_f(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, dialect, error_bad_lines, warn_bad_lines, delim_whitespace, low_memory, memory_map, float_precision)
674 )
675
--> 676 return _read(filepath_or_buffer, kwds)
677
678 parser_f.__name__ = name
/usr/local/lib/python3.6/dist-packages/pandas/io/parsers.py in _read(filepath_or_buffer, kwds)
446
447 # Create the parser.
--> 448 parser = TextFileReader(fp_or_buf, **kwds)
449
450 if chunksize or iterator:
/usr/local/lib/python3.6/dist-packages/pandas/io/parsers.py in __init__(self, f, engine, **kwds)
878 self.options["has_index_names"] = kwds["has_index_names"]
879
--> 880 self._make_engine(self.engine)
881
882 def close(self):
/usr/local/lib/python3.6/dist-packages/pandas/io/parsers.py in _make_engine(self, engine)
1112 def _make_engine(self, engine="c"):
1113 if engine == "c":
-> 1114 self._engine = CParserWrapper(self.f, **self.options)
1115 else:
1116 if engine == "python":
/usr/local/lib/python3.6/dist-packages/pandas/io/parsers.py in __init__(self, src, **kwds)
1889 kwds["usecols"] = self.usecols
1890
-> 1891 self._reader = parsers.TextReader(src, **kwds)
1892 self.unnamed_cols = self._reader.unnamed_cols
1893
pandas/_libs/parsers.pyx in pandas._libs.parsers.TextReader.__cinit__()
pandas/_libs/parsers.pyx in pandas._libs.parsers.TextReader._setup_parser_source()
FileNotFoundError: [Errno 2] File california_housing_train.csv does not exist: 'california_housing_train.csv'
# reduce the size of the dataset
housing_train = housing_train.sample(500)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-3-06adfb8f9262> in <module>
1 # reduce the size of the dataset
----> 2 housing_train = housing_train.sample(500)
NameError: name 'housing_train' is not defined
# show the data
housing_train.head()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-4-fb6f77579382> in <module>
1 # show the data
----> 2 housing_train.head()
NameError: name 'housing_train' is not defined
# Describe the target
housing_train['median_house_value'].describe()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-5-b4233862d098> in <module>
1 # Describe the target
----> 2 housing_train['median_house_value'].describe()
NameError: name 'housing_train' is not defined
# create the target
housing_train['high_price']=np.where(housing_train['median_house_value']>=187250, 1, 0)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-6-d4e460777f31> in <module>
1 # create the target
----> 2 housing_train['high_price']=np.where(housing_train['median_house_value']>=187250, 1, 0)
NameError: name 'housing_train' is not defined
# establish the predictors and the target
X = housing_train.drop(['median_house_value','high_price'], axis=1)
y = housing_train['high_price']
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-7-ad512e7f5a6e> in <module>
1 # establish the predictors and the target
----> 2 X = housing_train.drop(['median_house_value','high_price'], axis=1)
3 y = housing_train['high_price']
NameError: name 'housing_train' is not defined
# train-test split
X_train, X_test, y_train, y_test = train_test_split(X , y, test_size=0.3, random_state=42 )
print('length of y-test:', len(y_test))
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-8-fb8477000f57> in <module>
1 # train-test split
----> 2 X_train, X_test, y_train, y_test = train_test_split(X , y, test_size=0.3, random_state=42 )
3 print('length of y-test:', len(y_test))
NameError: name 'X' is not defined
# instantiate the classifier
mymodel = RandomForestClassifier()
# fit on the training data
mymodel.fit(X_train, y_train)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-10-dce11ba4b65c> in <module>
1 # fit on the training data
----> 2 mymodel.fit(X_train, y_train)
NameError: name 'X_train' is not defined
# predict on the testing data
y_preds = mymodel.predict(X_test)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-11-024502ef39a0> in <module>
1 # predict on the testing data
----> 2 y_preds = mymodel.predict(X_test)
NameError: name 'X_test' is not defined
# check out the first few houses
print(y_test.values[:10], 'true')
print(y_preds[:10], 'predicted')
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-12-090ae3e3bbe8> in <module>
1 # check out the first few houses
----> 2 print(y_test.values[:10], 'true')
3 print(y_preds[:10], 'predicted')
NameError: name 'y_test' is not defined
# evaluate the model performance
print('accuracy score: ', round(metrics.accuracy_score(y_test, y_preds),2))
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-13-12457152658f> in <module>
1 # evaluate the model performance
----> 2 print('accuracy score: ', round(metrics.accuracy_score(y_test, y_preds),2))
NameError: name 'y_test' is not defined
Confusion Matrix
# examine the confusion matrix
cm = pd.DataFrame(metrics.confusion_matrix(y_test, y_preds), columns=['pred_0', 'pred_1'])
cm
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-14-b56db60f4065> in <module>
1 # examine the confusion matrix
----> 2 cm = pd.DataFrame(metrics.confusion_matrix(y_test, y_preds), columns=['pred_0', 'pred_1'])
3 cm
NameError: name 'y_test' is not defined
- true positives (TP): These are cases in which we predicted yes (the median house value is high), and it is indeed high.
- true negatives (TN): We predicted no (the median house value is not high), and it is indeed not high.
- false positives (FP): We predicted yes (high median house value), but the median house value is not high. (Also known as a “Type I error.”)
- false negatives (FN): We predicted no (low median house value), but the house value is actually high. (Also known as a “Type II error.”)
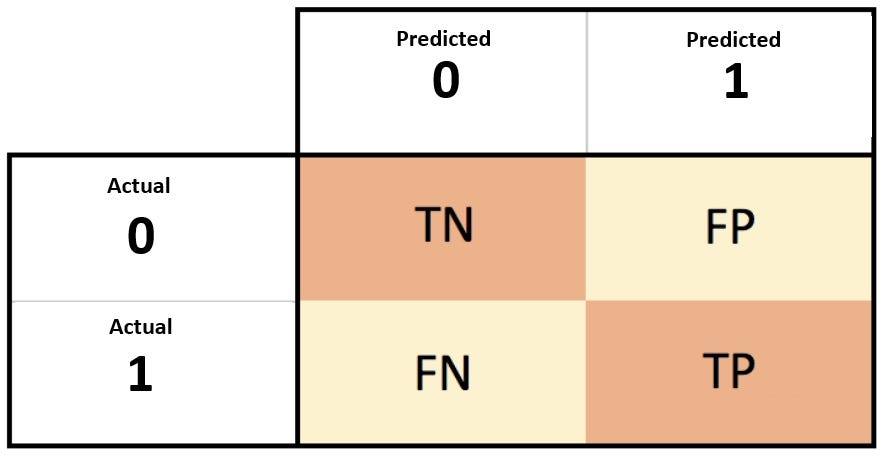
SOURCE: https://towardsdatascience.com/demystifying-confusion-matrix-29f3037b0cfa
Sometimes the order of the cells is reversed, as follows:

SOURCE: https://towardsdatascience.com/machine-learning-an-error-by-any-other-name-a7760a702c4d
# get the numbers
TN=cm['pred_0'].values[0]
FN=cm['pred_0'].values[1]
FP=cm['pred_1'].values[0]
TP=cm['pred_1'].values[1]
TOTAL=cm.values.sum()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-15-565b8b8acb9c> in <module>
1 # get the numbers
----> 2 TN=cm['pred_0'].values[0]
3 FN=cm['pred_0'].values[1]
4 FP=cm['pred_1'].values[0]
5 TP=cm['pred_1'].values[1]
NameError: name 'cm' is not defined
print('True Negatives:', TN)
print('False Negatives:', FN)
print('False Positives:', FP)
print('True Positives:', TP)
print('All:', TOTAL)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-16-4bbc85446297> in <module>
----> 1 print('True Negatives:', TN)
2 print('False Negatives:', FN)
3 print('False Positives:', FP)
4 print('True Positives:', TP)
5 print('All:', TOTAL)
NameError: name 'TN' is not defined
Accuracy:
Overall, how often is the model correct?
print(f'Accuracy: {round((TP + TN)/TOTAL, 2)}')
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-17-792a4c3139d9> in <module>
----> 1 print(f'Accuracy: {round((TP + TN)/TOTAL, 2)}')
NameError: name 'TP' is not defined
True Positive Rate:
When the answer is actually yes, how often does the model predict yes?
“Sensitivity” or “Recall”
print(f'True Positive Rate: {round(TP/ (TP + FN), 2)}')
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-18-3de1016ed889> in <module>
----> 1 print(f'True Positive Rate: {round(TP/ (TP + FN), 2)}')
NameError: name 'TP' is not defined
False Positive Rate:
When the answer is actually no, how often does the model predict yes?
Also known as “Fall-out Rate”
print(f'False Positive Rate: {round(FP / (TN + FP), 2)}')
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-19-82ad2cbd3933> in <module>
----> 1 print(f'False Positive Rate: {round(FP / (TN + FP), 2)}')
NameError: name 'FP' is not defined
Precision:
When the model predicts yes, how often is it correct?
Also known as “Positive Predictive Value (PPV)”
print(f'Precision: {round(TP / (TP + FP), 2)}')
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-20-edea803895c1> in <module>
----> 1 print(f'Precision: {round(TP / (TP + FP), 2)}')
NameError: name 'TP' is not defined
Specificity:
When the answer actually no, how often does the model predict no?
also known as “True Negative Rate”
print(f'Specificity: {round(TN / (TN + FP), 2)}')
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-21-4c50072979b8> in <module>
----> 1 print(f'Specificity: {round(TN / (TN + FP), 2)}')
NameError: name 'TN' is not defined
Prevalence:
How often does the yes condition actually occur in our sample?
actual yes/total
print(f'Prevalence: {round((TP + FN) / TOTAL, 2)}')
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-22-9fa514dcb5d7> in <module>
----> 1 print(f'Prevalence: {round((TP + FN) / TOTAL, 2)}')
NameError: name 'TP' is not defined
Queue Rate:
What percentage of the dataset is getting flagged as positive?
print(f'Queue Rate: {round((TP + FP) / TOTAL, 2)}')
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-23-f18175949cc6> in <module>
----> 1 print(f'Queue Rate: {round((TP + FP) / TOTAL, 2)}')
NameError: name 'TP' is not defined
Again
# House age
housing_train['housing_median_age'].describe()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-24-4344f81dd36f> in <module>
1 # House age
----> 2 housing_train['housing_median_age'].describe()
NameError: name 'housing_train' is not defined
# Create a target
housing_train['old']=np.where(housing_train['housing_median_age']>=28, 1, 0)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-25-73299b6cabec> in <module>
1 # Create a target
----> 2 housing_train['old']=np.where(housing_train['housing_median_age']>=28, 1, 0)
NameError: name 'housing_train' is not defined
# establish the predictors and the target
X = housing_train.drop(['housing_median_age','high_price', 'old'], axis=1)
y = housing_train['old']
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-26-9e7a76ff3333> in <module>
1 # establish the predictors and the target
----> 2 X = housing_train.drop(['housing_median_age','high_price', 'old'], axis=1)
3 y = housing_train['old']
NameError: name 'housing_train' is not defined
# train-test split
X_train, X_test, y_train, y_test = train_test_split(X , y, test_size=0.3, random_state=42 )
print('length of y-test:', len(y_test))
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-27-fb8477000f57> in <module>
1 # train-test split
----> 2 X_train, X_test, y_train, y_test = train_test_split(X , y, test_size=0.3, random_state=42 )
3 print('length of y-test:', len(y_test))
NameError: name 'X' is not defined
# instantiate the classifier
mymodel = RandomForestClassifier()
# fit on the training data
mymodel.fit(X_train, y_train)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-29-dce11ba4b65c> in <module>
1 # fit on the training data
----> 2 mymodel.fit(X_train, y_train)
NameError: name 'X_train' is not defined
# predict on the testing data
y_preds = mymodel.predict(X_test)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-30-024502ef39a0> in <module>
1 # predict on the testing data
----> 2 y_preds = mymodel.predict(X_test)
NameError: name 'X_test' is not defined
# check out the first few houses
print(y_test.values[:10], 'true')
print(y_preds[:10], 'predicted')
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-31-090ae3e3bbe8> in <module>
1 # check out the first few houses
----> 2 print(y_test.values[:10], 'true')
3 print(y_preds[:10], 'predicted')
NameError: name 'y_test' is not defined
# evaluate the model performance
print('accuracy score: ', round(metrics.accuracy_score(y_test, y_preds),2))
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-32-12457152658f> in <module>
1 # evaluate the model performance
----> 2 print('accuracy score: ', round(metrics.accuracy_score(y_test, y_preds),2))
NameError: name 'y_test' is not defined
# examine the confusion matrix
cm = pd.DataFrame(metrics.confusion_matrix(y_test, y_preds), columns=['pred_0', 'pred_1'])
cm
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-33-b56db60f4065> in <module>
1 # examine the confusion matrix
----> 2 cm = pd.DataFrame(metrics.confusion_matrix(y_test, y_preds), columns=['pred_0', 'pred_1'])
3 cm
NameError: name 'y_test' is not defined
# get the numbers
TN=cm['pred_0'].values[0]
FN=cm['pred_0'].values[1]
FP=cm['pred_1'].values[0]
TP=cm['pred_1'].values[1]
ALL=cm.values.sum()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-34-9ad4b010cbd6> in <module>
1 # get the numbers
----> 2 TN=cm['pred_0'].values[0]
3 FN=cm['pred_0'].values[1]
4 FP=cm['pred_1'].values[0]
5 TP=cm['pred_1'].values[1]
NameError: name 'cm' is not defined
print(f'Accuracy: {round((TP + TN)/TOTAL, 2)}')
print(f'True Positive Rate: {round(TP/ (TP + FN), 2)}')
print(f'False Positive Rate: {round(FP / (TN + FP), 2)}')
print(f'Precision: {round(TP / (TP + FP), 2)}')
print(f'Specificity: {round(TN / (TN + FP), 2)}')
print(f'Prevalence: {round(TP + FN / TOTAL, 2)}')
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-35-86a7483b4783> in <module>
----> 1 print(f'Accuracy: {round((TP + TN)/TOTAL, 2)}')
2 print(f'True Positive Rate: {round(TP/ (TP + FN), 2)}')
3 print(f'False Positive Rate: {round(FP / (TN + FP), 2)}')
4 print(f'Precision: {round(TP / (TP + FP), 2)}')
5 print(f'Specificity: {round(TN / (TN + FP), 2)}')
NameError: name 'TP' is not defined
Terminology
| Bayes term | Bayes formula | Confusion Matrix term | Confusion Matrix formula | Alternative CM term |
|---|---|---|---|---|
| prior | P(A) | prevalence | (TP + FN) / (TP+TN+FP+FN) | ? |
| posterior | P(A given B) | Positive Predictive Value (PPV) | TP / (TP + FP) | precision |
| conditional | P(B given A) | True Positive Rate (TPR) | TP / (TP + FN) | sensitivity, recall |
| marginal | P(B) | queue rate | (TP + FP) / (TP+TN+FP+FN) | ? |
| prior complement | P(not A) or 100-P(A) | prevalence complement | 1-prevalence | ? |
| ? | P(not B given not A) | True Negative Rate (TNR) | TN / (FP + TN) | specificity |
| ? | P(B given not A) | False Positive Rate (FPR) | FP / (FP+TN) | fall-out rate, false alarm rate |
| ? | P(not B given A) | False Negative Rate (FNR) | FN / (TP + FN) | miss rate |
| ? | ? | accuracy | (TP + TN) / (TP+TN+FP+FN) | ? |
| ? | ? | error rate | (FP + FN) / (TP+TN+FP+FN) | misclassification rate |
Abbreviations
A: Hypothesized Data
B: Observed Data
TP: True Positive
TN: True Negative
FP: False Positive
FN: False Negative
^ Note: Sometimes in Bayesian statistics the following terms are used instead:
- prior = hypothesis
- posterior = updated hypothesis
- conditional = likelihood
- marginal = model evidence
Problem 1. Drunk Drivers
imagine that individuals are taking a breathalyzer test with
- an 8% false positive rate,
- a 100% true positive rate,
- our prior belief about drunk driving in the population is 1/1000.
- What is the probability that a person is drunk after one positive breathalyzer test?
def prob_drunk_given_positive(prob_drunk_prior, false_positive_rate, true_positive_rate):
prob_non_drunk = 1 - prob_drunk_prior
numerator = (true_positive_rate*prob_drunk_prior)
denomenator = ((true_positive_rate*prob_drunk_prior) + (false_positive_rate*prob_non_drunk))
posterior_probability = (numerator / denomenator)
return posterior_probability
# Probability that a person is drunk after one breathalyzer test:
posterior = prob_drunk_given_positive(1/1000, .08, 1)
print('{:.4f}'.format(posterior))
0.0124
Problem 2: Marginal is provided
Solving for the posterior is not too complicated when the marginal probability is provided for you.
Suppose we have an online website where we sell a gizmo. Consider the case where a website-visitor clicks to expand the gizmo’s product description. What is the probability that they will then purchase the gizmo?
Let’s assume some details:
- 10 percent of site visitors buy the gizmo. That’s the prior: P(buy).
-
7 percent of site visitors that purchased the gizmo also clicked on the description. That’s the conditional: P(click buy). - 5 percent of site visitors click on the product description. That’s the marginal: P(click).
-
What percent of site visitors will purchase the gizmo after clicking on the description? That’s the posterior: P(buy click).
Let’s plug what we know into the theorem:
-
P(A B) = P(B A) * P(A) / P(B) -
P(buy click) = P(click buy) * P(buy) / P(click)
# input the prior, marginal, and conditional.
p_a = 0.10
p_b = 0.05
p_b_given_a = 0.07
# write the formula
def bayes_w_marginal(p_a, p_b, p_b_given_a):
p_a_given_b = (p_b_given_a * p_a) / p_b
return p_a_given_b
# plug it in
result = bayes_w_marginal(p_a, p_b, p_b_given_a)
print('P(A|B) = {:.3f}%'.format(result * 100))
P(A|B) = 14.000%
Problem 3: No marginal provided!
Solving for the posterior is a little harder when the marginal is not provided; most real-world problems fall into this pattern.
Consider the case where we receive an email and the spam detector flags it (i.e., puts it in the spam folder). What is the probability it was actally spam?
Let’s assume some details:
- 2 percent of the email we receive is spam – that’s the prior: P(Spam).
-
the spam detector is really good and when an email is spam, it flags it 99 percent of the time – that’s the conditional: P(Flagged Spam). -
When an email is not spam, it will flag it with a very low rate of 0.1 percent – that’s the fall-out rate: P(Flagged not Spam). -
What is the probability that a flagged email is actually spam? – that’s the posterior: P(Spam Flagged)
Let’s plug what we know into the theorem:
-
P(A B) = P(B A) * P(A) / P(B) -
P(Spam Flagged) = P(Flagged Spam) * P(Spam) / P(Flagged)
We don’t know P(B), that is P(Flagged), but we can calculate it as follows:
-
P(B) = P(B A) * P(A) + P(B not A) * P(not A) -
P(Flagged) = P(Flagged Spam) * P(Spam) + P(Flagged not Spam) * P(not Spam)
# input the prior, conditional, and fall-out rate.
p_a = 0.02
p_b_given_a = 0.99
p_b_given_not_a = 0.001
# write the formula
def bayes_no_marginal(p_a, p_b_given_a, p_b_given_not_a):
not_a = 1 - p_a
p_b = p_b_given_a * p_a + p_b_given_not_a * not_a
p_a_given_b = (p_b_given_a * p_a) / p_b
return p_a_given_b
# plug it in
posterior = bayes_no_marginal(p_a, p_b_given_a, p_b_given_not_a)
print('P(A|B) = {:.3f}%'.format(posterior * 100))
P(A|B) = 95.284%
Problem 4. No marginal (again)
What if only two pieces of information are available?
Let’s assume some details:
- the condition occurs in 2% of the population – that’s the prior: P(sick).
-
when a patient is actually sick, the classifier flags them as sick 72 percent of the time – that’s the conditional: P(Flagged Sick). -
when the classifier says they are not sick, this is true 97 percent of the time. That’s P(not Flagged not Sick) -
What is the probability that a flagged patient is actually sick? – that’s the posterior: P(Sick Flagged).
| We don’t know the marginal P(B), and we don’t know the fall-out rate – P(Flagged | not Sick) – but we can calculate them using the formulas: |
-
P(B) = P(B A) * P(A) + P(B not A) * P(not A) -
P(B not A) = 1 – P(not B not A)
Which translates to:
-
P(Flagged) = P(Flagged Sick) * P(Sick) + P(Flagged not Sick) * P(not Sick) -
P(Flagged not Sick) = 1 - P(not Flagged not Sick)
# input the prior, conditional, and P(not B|not A).
p_a = 0.02
p_b_given_a = 0.72
p_not_b_given_not_a = 0.97
# write the formula:
def bayes_no_marginal_no_fallout(p_a, p_b_given_a, p_not_b_given_not_a):
not_a = 1 - p_a
p_b_given_not_a = 1 - p_not_b_given_not_a
p_b = p_b_given_a * p_a + p_b_given_not_a * not_a
p_a_given_b = (p_b_given_a * p_a) / p_b
return p_a_given_b
# plug it in:
posterior = bayes_no_marginal_no_fallout(p_a, p_b_given_a, p_not_b_given_not_a)
print('P(A|B) = {:.3f}%'.format(posterior * 100))
P(A|B) = 32.877%
Sources:
- http://learningwithdata.com/bayes-primer.html#bayes-primer
- https://machinelearningmastery.com/intuition-for-bayes-theorem-with-worked-examples/
- https://www.bayestheorem.net/
- https://lucdemortier.github.io/articles/16/PerformanceMetrics
- https://towardsdatascience.com/machine-learning-an-error-by-any-other-name-a7760a702c4d
- https://ncss-wpengine.netdna-ssl.com/wp-content/themes/ncss/pdf/Procedures/NCSS/Binary_Diagnostic_Tests-Single_Sample.pdf
- https://www.dataschool.io/simple-guide-to-confusion-matrix-terminology/
- https://online.stat.psu.edu/stat507/node/71/